
0. 관련 포스팅
1. 개요
JPA 를 활용한 개발 중에
@ManyToOne, @OneToMany, @OneToOne 등으로
연관된 경우 Entity를 같이 조회해야하는 경우가 발생한다.
이때 Fetch Join을 사용하지 않고 연관 Entity를 사용하게 되면 N+1 문제가 발생한다.

a. N + 1 문제란?
JPA에서는 영속성 컨텍스트라는 말이 자주 나온다.
데이터 베이스에서 데이터를 불러오면 1차 캐시에 저장이 되면서 영속성을 가진다 하는데,
이 상태에서는 변경 감지나 동일성 보장, 트랜잭션 내 쓰기지연 등의 기능을 제공하게 된다.
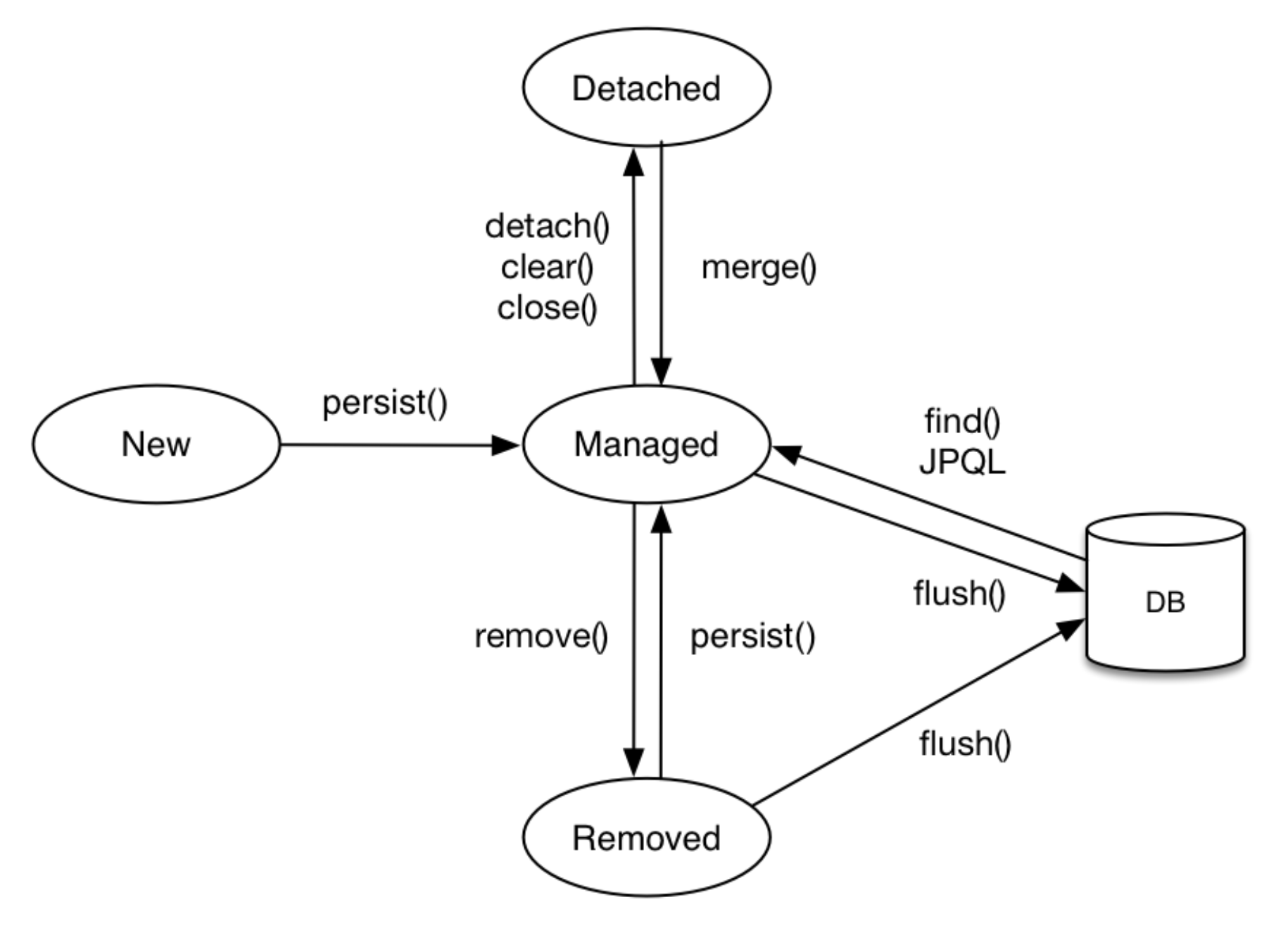
이때 지연 로딩 기능에 대해서도 나오는데,
지연 로딩은 연관된 Entity를 바로 조회하지 않고 사용 시에 조회하는 기능이다.
그렇기 때문에 연관관계에 있는 Entity를 애플리케이션 내에서 호출하게 되면
연관 데이터 갯수만큼 SQL 이 한번 더 나가는 상황이 발생한다.
(영속성 컨텍스트에 존재하지 않을 경우 SQL이 데이터베이스에 요청되기 때문)
b. Fetch Join
이때 연관된 Entity를 같이 영속화 할때 사용 되는 것이 Fetch Join 이다.
Fetch Join 은 Entity 조회 시,
연관 데이터를 함께 Join으로 가져오는 것을 말하는데
연관 Entity를 Join으로 Query를 한번에 데이터를 요청하기 때문에 이점이 있다.

이는 SQL 에서의 용어가 아닌 JPA 내에서의 Fetch Join 이니 혼동하지 않아야한다.
애플리케이션에서 작성 시 Query를 'join fetch' 로 적어주고 실제 Sql 상으로는 join이 나가는 것을 볼 수 있다.
(Sql에서 그냥 join 은 default 값으로 inner join에 해당한다.)
2. Test
테스트용으로 데이터를 아래 이미지와 같이 넣어주었다.


a. 구현
테스트 코드에서는 Member(회원)와 Board(게시글)의 연관관계는 1:N 관계를 가지고 있고
아래와 같이 간단하게 Repository와 Service 메소드를 구현하였다.
MemberRepository
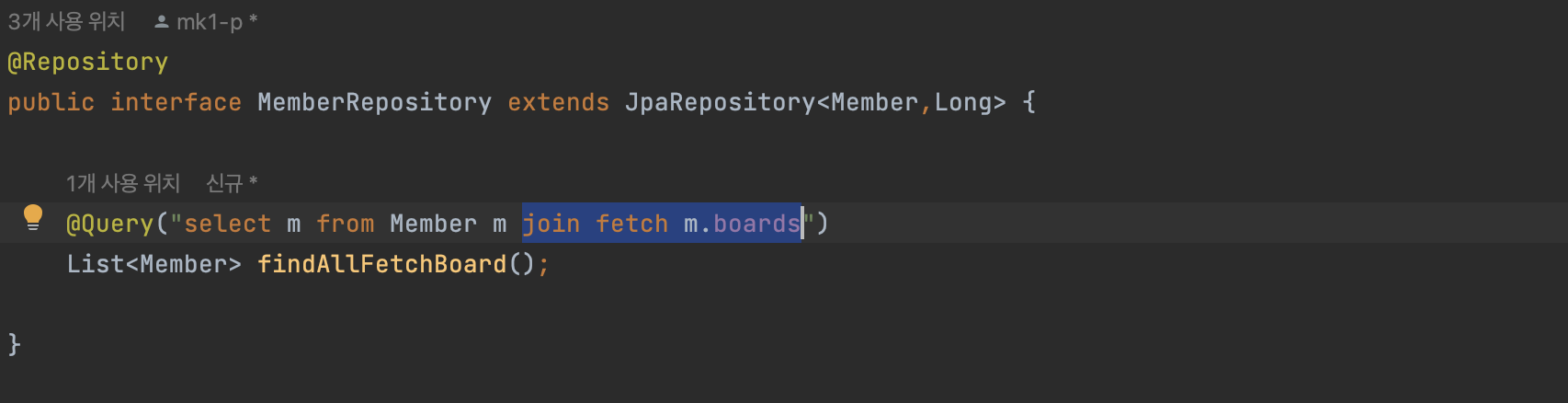
- findAllFetchBoard() : Member와 연관된 Board Fetch Join 용 메소드
MemberService
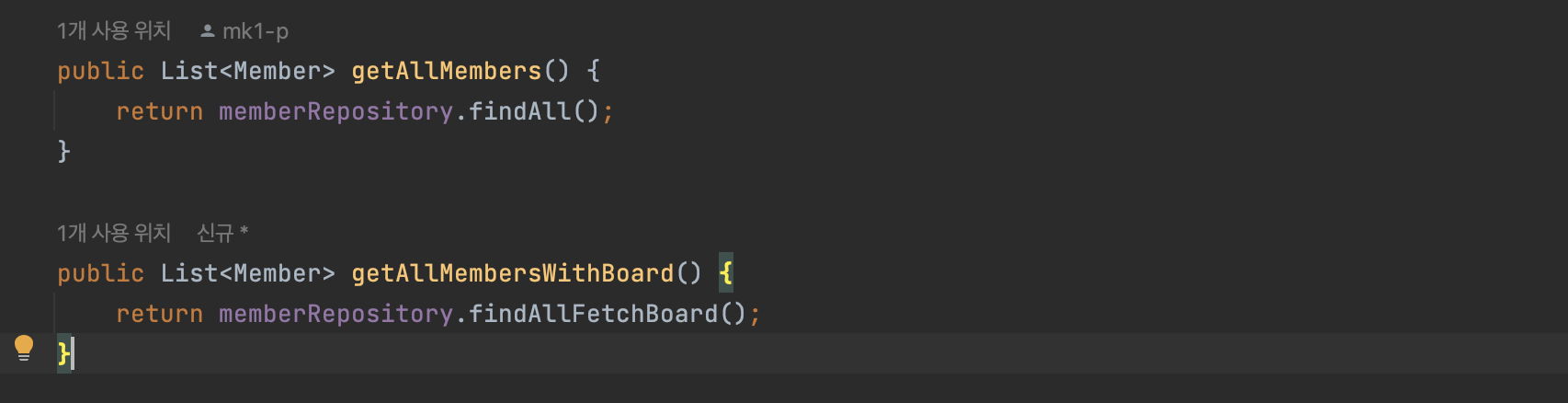
- getAllMembers() : Member 전체 조회
- getAllMembersWithBoard() : Meber 전체 조회 + Board Fetch Join
b. Run Test Code
아래 Fetch Join이 적용되지 않은 경우와 된 경우,
두가지의 간단한 코드와 실행 됐을때의 로그이다.
Fetch가 적용되지 않은 경우
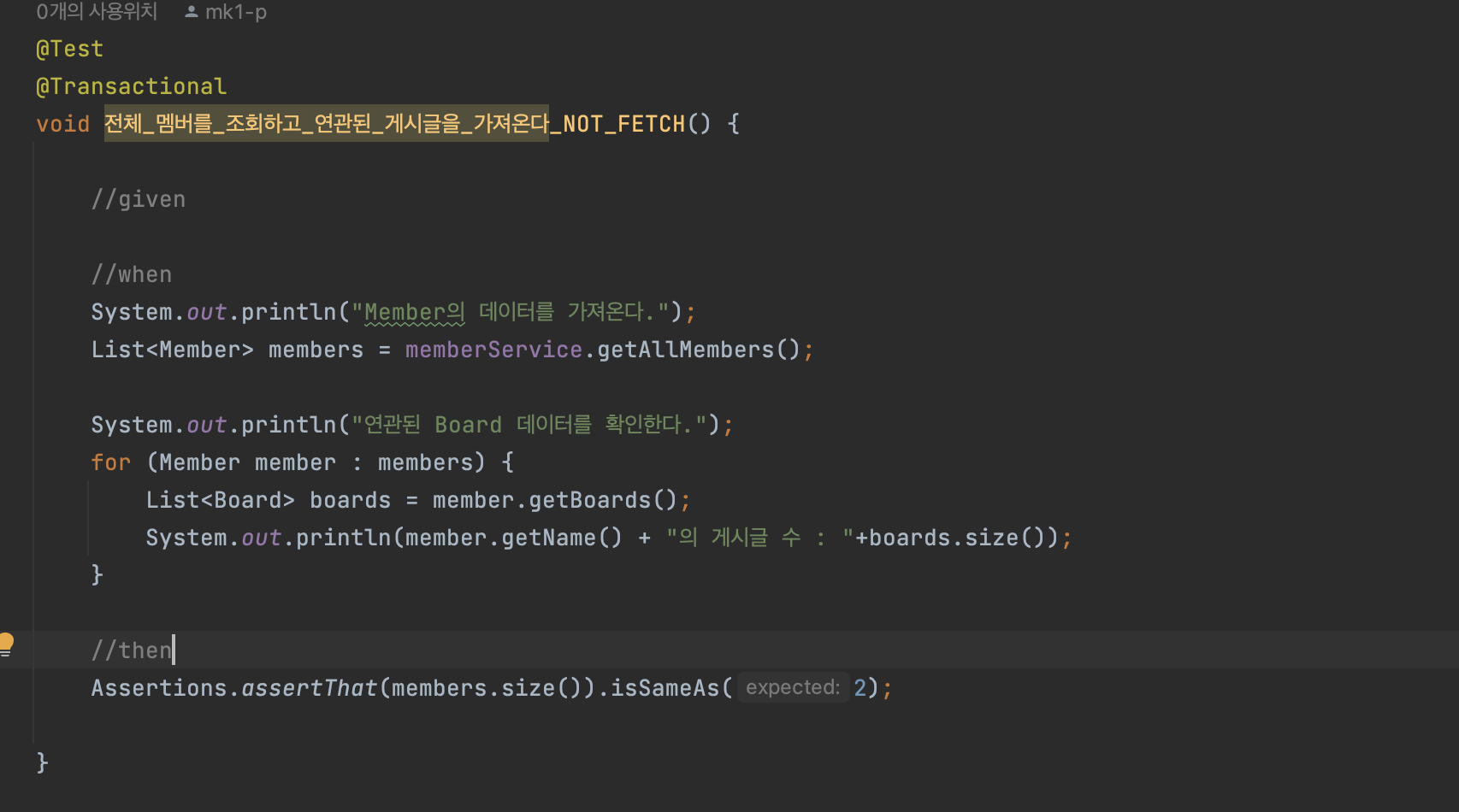

로그에서 볼수 있듯이,
Board 객체가 사용될때 데이터베이스에서 가져오는 것을 볼 수 있다.
테스트 상에서는 데이터가 많지 않기 때문에 3번의 Query가 나갔지만,
실 서비스 상에서는 데이터가 이보다 많기 때문에 수많은 쿼리가 발생한다.
Fetch가 적용된 경우


위의 Fetch Join 미 적용 테스트와는 다르게
Board 객체를 사용하더라도 Query가 나가지 않는 것을 볼 수 있는데,
처음 Member를 조회하면서 Board를 Join 하는 질의문을 사용하였기에
Member와 연관된 Board Entity의 영속화가 함께 진행되었기 때문이다.
물론,
Query 작성 시에 'join fetch' 이 아닌 Sql의 join(left, inner, right 등)을 적을 경우에는 다르다.
일반 join 을 적용할 경우에는 Fetch Join과 다르게 영속화가 되지 않기에 이점을 주의해야한다.
3. 단점
Fetch Join 시에는 페이징이 불가능 하다는 단점이 존재한다.

물론 위의 코드 처럼 기능 상으로는 사용할 수 있지만,
데이터베이스에서 데이터를 가져온 후 애플리케이션에서 페이징, 솔팅을 진행하기 때문에
메모리 누수의 위험이 존재한다.

Query 작성을 많이 해본 분들은 알겠지만,
Join 시에 Group By 하지 않으면 연관에 연관으로 중복된 데이터가 나타나는 경험을 하신분들은 쉽게 이해하실 수 있을텐데
데이터베이스에서 모든 데이터를 가져오고 distinct 가 있으면 애플리케이션에서 중복 제거를 하고
페이징 또는 솔팅이 있다면 이때 작업을 하게 된다.
위에서 페이징 시 어떤 데이터를 주체로 정렬 및 페이징을 해야하는지 데이터베이스 상에서는 알수 없기에
Hibernate 가 전체 데이터를 가져와 페이징 작업을 진행하기 때문이다.
이에 대한 좀더 자세한 내용은 활용에 관한 포스팅에서 이어갈 예정이다.
4. 마무리
N+1 문제를 해결하기 위한 Fetch Join에 대해 알아보았는데
Fetch Join 또한 장단점이 있기 때문에,
상황에 맞게 선택하여 구현하는 것이 좋다.
김영한님의 '실전! 스프링 부트와 JPA 활용2' 강의에서는
~ToOne 에서 Fetch Join 을 사용하고,
~ToMany 에서는 Fetch Join을 사용하더라도 하나의 Entity 에만 적용하는 방향으로 알려주고 있다.
한 개의 연관관계를 Fetch Join으로 가져올 경우는 병렬로 하나씩 늘어나는 반면,
여러 개의 연관 데이터를 가진 경우는 1:N:N 의 관계를 가질 수 있기 때문에 한 개 이상의 Fetch Join을 피하라고 하고 있다.
5. 깃허브
GitHub - mk1-p/jpa-sample-code: Test for Spring JPA
Test for Spring JPA. Contribute to mk1-p/jpa-sample-code development by creating an account on GitHub.
github.com
6. 참고자료
[JPA] 일반 Join과 Fetch Join의 차이
JPA를 사용하다 보면 바로 N+1의 문제에 마주치고 바로 Fetch Join을 접하게 됩니다. 처음 Fetch Join을 접했을 때 왜 일반 Join으로 해결하면 안되는지에 대해 명확히 정리가 안된 채로 Fetch Join을 사용했
cobbybb.tistory.com
실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 - 인프런 | 강의
스프링 부트와 JPA를 활용해서 API를 개발합니다. 그리고 JPA 극한의 성능 최적화 방법을 학습할 수 있습니다., 스프링 부트, 실무에서 잘 쓰고 싶다면? 복잡한 문제까지 해결하는 힘을 길러보세요
www.inflearn.com
N+1 문제 - Incheol's TECH BLOG
Query를 실행하도록 지원해주는 다양한 플러그인이 있다. 대표적으로 Mybatis, QueryDSL, JOOQ, JDBC Template 등이 있을 것이다. 이를 사용하면 로직에 최적화된 쿼리를 구현할 수 있다.
incheol-jung.gitbook.io
'DEV > Spring' 카테고리의 다른 글
| [JPA] JoinColumns 조회 방식 (0) | 2023.10.12 |
|---|---|
| [JPA] Fetch Join 활용 (1) | 2023.10.11 |
| [Spring] 권한 순서 정하기 (RoleHierarchy : 역할계층) (0) | 2023.09.17 |
| [Spring] API Path Prefix 설정하기 (1) | 2023.09.14 |
| [Spring] WebClient 란? (0) | 2023.08.30 |
0. 관련 포스팅
1. 개요
JPA 를 활용한 개발 중에
@ManyToOne, @OneToMany, @OneToOne 등으로
연관된 경우 Entity를 같이 조회해야하는 경우가 발생한다.
이때 Fetch Join을 사용하지 않고 연관 Entity를 사용하게 되면 N+1 문제가 발생한다.
a. N + 1 문제란?
JPA에서는 영속성 컨텍스트라는 말이 자주 나온다.
데이터 베이스에서 데이터를 불러오면 1차 캐시에 저장이 되면서 영속성을 가진다 하는데,
이 상태에서는 변경 감지나 동일성 보장, 트랜잭션 내 쓰기지연 등의 기능을 제공하게 된다.
이때 지연 로딩 기능에 대해서도 나오는데,
지연 로딩은 연관된 Entity를 바로 조회하지 않고 사용 시에 조회하는 기능이다.
그렇기 때문에 연관관계에 있는 Entity를 애플리케이션 내에서 호출하게 되면
연관 데이터 갯수만큼 SQL 이 한번 더 나가는 상황이 발생한다.
(영속성 컨텍스트에 존재하지 않을 경우 SQL이 데이터베이스에 요청되기 때문)
b. Fetch Join
이때 연관된 Entity를 같이 영속화 할때 사용 되는 것이 Fetch Join 이다.
Fetch Join 은 Entity 조회 시,
연관 데이터를 함께 Join으로 가져오는 것을 말하는데
연관 Entity를 Join으로 Query를 한번에 데이터를 요청하기 때문에 이점이 있다.
이는 SQL 에서의 용어가 아닌 JPA 내에서의 Fetch Join 이니 혼동하지 않아야한다.
애플리케이션에서 작성 시 Query를 'join fetch' 로 적어주고 실제 Sql 상으로는 join이 나가는 것을 볼 수 있다.
(Sql에서 그냥 join 은 default 값으로 inner join에 해당한다.)
2. Test
테스트용으로 데이터를 아래 이미지와 같이 넣어주었다.
a. 구현
테스트 코드에서는 Member(회원)와 Board(게시글)의 연관관계는 1:N 관계를 가지고 있고
아래와 같이 간단하게 Repository와 Service 메소드를 구현하였다.
MemberRepository
- findAllFetchBoard() : Member와 연관된 Board Fetch Join 용 메소드
MemberService
- getAllMembers() : Member 전체 조회
- getAllMembersWithBoard() : Meber 전체 조회 + Board Fetch Join
b. Run Test Code
아래 Fetch Join이 적용되지 않은 경우와 된 경우,
두가지의 간단한 코드와 실행 됐을때의 로그이다.
Fetch가 적용되지 않은 경우
로그에서 볼수 있듯이,
Board 객체가 사용될때 데이터베이스에서 가져오는 것을 볼 수 있다.
테스트 상에서는 데이터가 많지 않기 때문에 3번의 Query가 나갔지만,
실 서비스 상에서는 데이터가 이보다 많기 때문에 수많은 쿼리가 발생한다.
Fetch가 적용된 경우
위의 Fetch Join 미 적용 테스트와는 다르게
Board 객체를 사용하더라도 Query가 나가지 않는 것을 볼 수 있는데,
처음 Member를 조회하면서 Board를 Join 하는 질의문을 사용하였기에
Member와 연관된 Board Entity의 영속화가 함께 진행되었기 때문이다.
물론,
Query 작성 시에 'join fetch' 이 아닌 Sql의 join(left, inner, right 등)을 적을 경우에는 다르다.
일반 join 을 적용할 경우에는 Fetch Join과 다르게 영속화가 되지 않기에 이점을 주의해야한다.
3. 단점
Fetch Join 시에는 페이징이 불가능 하다는 단점이 존재한다.
물론 위의 코드 처럼 기능 상으로는 사용할 수 있지만,
데이터베이스에서 데이터를 가져온 후 애플리케이션에서 페이징, 솔팅을 진행하기 때문에
메모리 누수의 위험이 존재한다.
Query 작성을 많이 해본 분들은 알겠지만,
Join 시에 Group By 하지 않으면 연관에 연관으로 중복된 데이터가 나타나는 경험을 하신분들은 쉽게 이해하실 수 있을텐데
데이터베이스에서 모든 데이터를 가져오고 distinct 가 있으면 애플리케이션에서 중복 제거를 하고
페이징 또는 솔팅이 있다면 이때 작업을 하게 된다.
위에서 페이징 시 어떤 데이터를 주체로 정렬 및 페이징을 해야하는지 데이터베이스 상에서는 알수 없기에
Hibernate 가 전체 데이터를 가져와 페이징 작업을 진행하기 때문이다.
이에 대한 좀더 자세한 내용은 활용에 관한 포스팅에서 이어갈 예정이다.
4. 마무리
N+1 문제를 해결하기 위한 Fetch Join에 대해 알아보았는데
Fetch Join 또한 장단점이 있기 때문에,
상황에 맞게 선택하여 구현하는 것이 좋다.
김영한님의 '실전! 스프링 부트와 JPA 활용2' 강의에서는
~ToOne 에서 Fetch Join 을 사용하고,
~ToMany 에서는 Fetch Join을 사용하더라도 하나의 Entity 에만 적용하는 방향으로 알려주고 있다.
한 개의 연관관계를 Fetch Join으로 가져올 경우는 병렬로 하나씩 늘어나는 반면,
여러 개의 연관 데이터를 가진 경우는 1:N:N 의 관계를 가질 수 있기 때문에 한 개 이상의 Fetch Join을 피하라고 하고 있다.
5. 깃허브
GitHub - mk1-p/jpa-sample-code: Test for Spring JPA
Test for Spring JPA. Contribute to mk1-p/jpa-sample-code development by creating an account on GitHub.
github.com
6. 참고자료
[JPA] 일반 Join과 Fetch Join의 차이
JPA를 사용하다 보면 바로 N+1의 문제에 마주치고 바로 Fetch Join을 접하게 됩니다. 처음 Fetch Join을 접했을 때 왜 일반 Join으로 해결하면 안되는지에 대해 명확히 정리가 안된 채로 Fetch Join을 사용했
cobbybb.tistory.com
실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 - 인프런 | 강의
스프링 부트와 JPA를 활용해서 API를 개발합니다. 그리고 JPA 극한의 성능 최적화 방법을 학습할 수 있습니다., 스프링 부트, 실무에서 잘 쓰고 싶다면? 복잡한 문제까지 해결하는 힘을 길러보세요
www.inflearn.com
N+1 문제 - Incheol's TECH BLOG
Query를 실행하도록 지원해주는 다양한 플러그인이 있다. 대표적으로 Mybatis, QueryDSL, JOOQ, JDBC Template 등이 있을 것이다. 이를 사용하면 로직에 최적화된 쿼리를 구현할 수 있다.
incheol-jung.gitbook.io
'DEV > Spring' 카테고리의 다른 글
| [JPA] JoinColumns 조회 방식 (0) | 2023.10.12 |
|---|---|
| [JPA] Fetch Join 활용 (1) | 2023.10.11 |
| [Spring] 권한 순서 정하기 (RoleHierarchy : 역할계층) (0) | 2023.09.17 |
| [Spring] API Path Prefix 설정하기 (1) | 2023.09.14 |
| [Spring] WebClient 란? (0) | 2023.08.30 |